ELK架构说明
一.ELK介绍
1.ELK简介
ELK是Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称(但是后期出现的filebeat(beats中的一种)可以用来替代logstash的数据收集功能,比较轻量级)。市面上也被成为Elastic Stack。
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。Filebeat的工作方式如下:启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
Logstash是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。Logstash能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用Grok从非结构化数据中派生出结构,从IP地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。
Elasticsearch是Elastic Stack核心的分布式搜索和分析引擎,是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。Elasticsearch为所有类型的数据提供近乎实时的搜索和分析。无论您是结构化文本还是非结构化文本,数字数据或地理空间数据,Elasticsearch都能以支持快速搜索的方式有效地对其进行存储和索引。
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。并且可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以汇总、分析和搜索重要数据日志。还可以让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态
2.为什么要使用ELK
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
往往单台机器的日志我们使用grep、awk等工具就能基本实现简单分析,但是当日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
3.完整日志系统基本特征
- 收集:能够采集多种来源的日志数据
- 传输:能够稳定的把日志数据解析过滤并传输到存储系统
- 存储:存储日志数据
- 分析:支持 UI 分析
- 警告:能够提供错误报告,监控机制
二.ELK架构分析
2.1、beats+elasticsearch+kibana模式
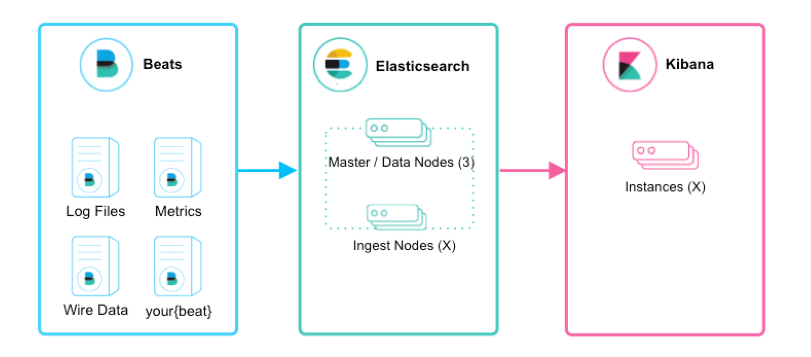
如上图所示,该ELK框架由beats(日志分析我们通常使用filebeat)+elasticsearch+kibana构成,这个框架比较简单,入门级的框架。其中filebeat也能通过module对日志进行简单的解析和索引。并查看预建的Kibana仪表板。
该框架适合简单的日志数据,一般可以用来玩玩,生产环境建议接入logstash
2.2、beats+logstash+elasticsearch+kibana模式
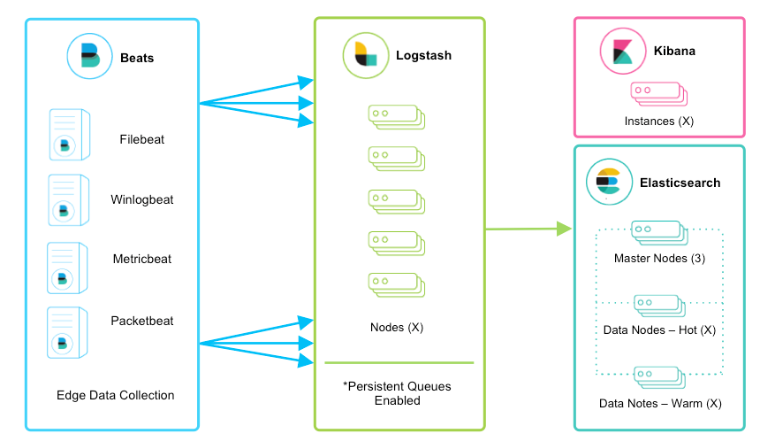
该框架是在上面的框架的基础上引入了logstash,引入logstash带来的好处如下:
- 通Logstash具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻背压
- 从其他数据源(例如数据库,S3或消息传递队列)中提取
- 将数据发送到多个目的地,例如S3,HDFS或写入文件
- 使用条件数据流逻辑组成更复杂的处理管道
filebeat结合logstash带来的优势:
1、水平可扩展性,高可用性和可变负载处理:filebeat和logstash可以实现节点之间的负载均衡,多个logstash可以实现logstash的高可用
2、消息持久性与至少一次交付保证:使用Filebeat或Winlogbeat进行日志收集时,可以保证至少一次交付。从Filebeat或Winlogbeat到Logstash以及从Logstash到Elasticsearch的两种通信协议都是同步的,并且支持确认。Logstash持久队列提供跨节点故障的保护。对于Logstash中的磁盘级弹性,确保磁盘冗余非常重要。
3、具有身份验证和有线加密的端到端安全传输:从Beats到Logstash以及从 Logstash到Elasticsearch的传输都可以使用加密方式传递 。与Elasticsearch进行通讯时,有很多安全选项,包括基本身份验证,TLS,PKI,LDAP,AD和其他自定义领域
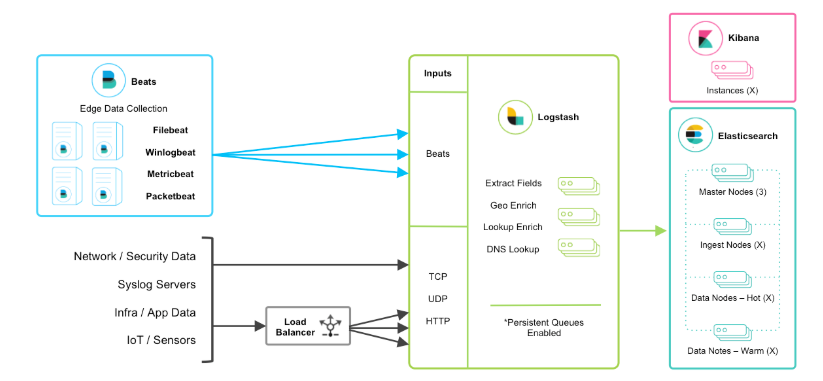
当然在该框架的基础上还可以引入其他的输入数据的方式:比如:TCP,UDP和HTTP协议是将数据输入Logstash的常用方法(如下图所示):
2.3、beats+缓存/消息队列+logstash+elasticsearch+kibana模式
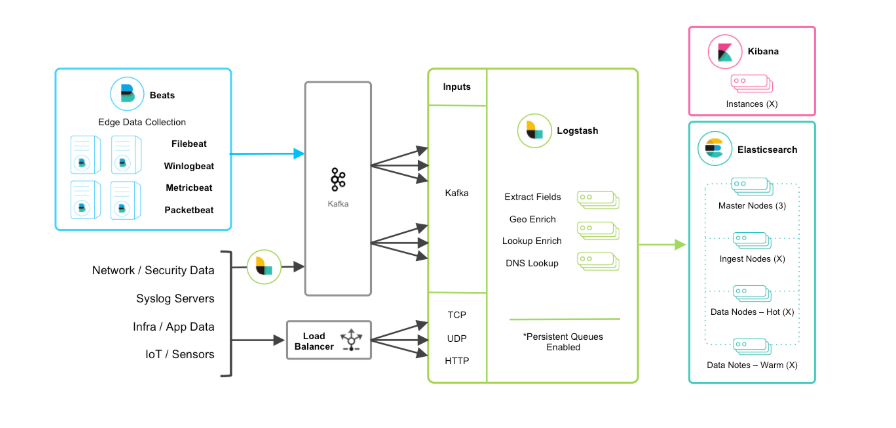
在如上的基础上我们可以在beats和logstash中间添加一些组件redis、kafka、RabbitMQ等,添加中间件将会有如下好处: 第一,降低对日志所在机器的影响,这些机器上一般都部署着反向代理或应用服务,本身负载就很重了,所以尽可能的在这些机器上少做事; 第二,如果有很多台机器需要做日志收集,那么让每台机器都向Elasticsearch持续写入数据,必然会对Elasticsearch造成压力,因此需要对数据进行缓冲,同时,这样的缓冲也可以一定程度的保护数据不丢失; 第三,将日志数据的格式化与处理放到Indexer中统一做,可以在一处修改代码、部署,避免需要到多台机器上去修改配置 ;
总结
消息系统主要功能
1、解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束 2、冗余 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的”插入-获取-删除”范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。 3、扩展性 因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。 4、灵活性 & 峰值处理能力 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。 如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。 5、可恢复性 系统的一部分组件失效时,不会影响到整个系统。 消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。 6、顺序保证 在大多使用场景下,数据处理的顺序都很重要。 大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka 保证一个 Partition 内的消息的有序性) 7、缓冲 有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。 8、异步通信 很多时候,用户不想也不需要立即处理消息。 消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
Redis与Kafka
我们都知道Redis是以key的hash方式来分散对列存储数据的,且Redis作为集群使用时,对应的应用对应一个Redis,在某种程度上会造成数据的倾斜性,从而导致数据的丢失。 而从之前我们部署Kafka集群来看,kafka的一个topic(主题),可以有多个partition(副本),而且是均匀的分布在Kafka集群上,这就不会出现redis那样的数据倾斜性。Kafka同时也具备Redis的冗余机制,像Redis集群如果有一台机器宕掉是很有可能造成数据丢失,而Kafka因为是均匀的分布在集群主机上,即使宕掉一台机器,是不会影响使用。同时Kafka作为一个订阅消息系统,还具备每秒百万级别的高吞吐量,持久性的、分布式的特点等。